
- 2018/07/20: 公開
- 2020/11/04: 細部を更新
こんにちは、hachi8833です。BPS社内勉強会でのkazzさんのスライドを元にした記事をお送りいたします。
RubyのEnumerableのコレクション系メソッドのいくつかを合間合間に再実装しながら進める構成になっています。
![⚓]() Rubyの
Rubyのforは原則使わないこと

Rubyである程度書けるようになれば、ループでforを使う人はまずいないと思います。Rubyスタイルガイド↓でも「2-07【統一】forは原則使わない」とあります。
# forの場合(まず使わない)
list = (1..5).to_a.freeze
for element in list
puts "forによる表示: #{element}"
end
# eachの場合
list = (1..5).to_a.freeze
list.each do |element|
puts "eachによる表示: #{element}"
end
![⚓]() 参考:
参考: #eachをforで実装して理解する
上のスタイルガイドにも「forの内部実装は#each」と記載されていますが、せっかくなので#eachをforで実装してみましょう。なおRubyのforはキーワードですが、#eachはメソッドです。
参考: Array#each (Ruby 2.7.0 リファレンスマニュアル)
# オレオレeach
def my_each(collection, &block)
for element in collection
yield(element)
end
collection
end
list = (1..5).to_a.freeze
my_each(list) do |e|
puts "yield経由: #{e}"
end
この#my_eachでは、forループの中でyield(element)を呼んでいます。yieldは、メソッドの外から注入された一連のコード(ブロック、Proc、lambdaなど)を実行します。

なお、引数の2番目にある&blockは省略しても動きますが、ここでは「このメソッドはブロックが必須である」ということを表すスタイルとして&blockを置いています。&blockを置くと、呼び出し時にブロックが渡されないとエラーになります。なおこの記法はスタイルなので必須ではありません。
block_given?でブロックの有無をチェックしてもよいのですが、&blockを置くことで、ブロック渡し忘れエラーをメソッド実行前の引数受け取りの段階で表示でき、メソッドが中途半端に実行されずに済むというメリットもあります。
![⚓]() 何でも
何でも#eachでやるのは非効率
ここからが本題です。
しかしループは#eachで書いておけばよいというものではありません。#eachがRubyの重要なメソッドであるのは確かですが、具体的な処理をループの中に記述するという意味では実は#eachはforと本質的に変わりません。何でも#eachでループ処理する癖を直さないと、forでやるのと同じく、C言語的な手続き型の発想に囚われたままになってしまいます。
以下は配列[1, 2, 3, 4, 5]の各要素を倍にしたものを返す簡単なコードですが、わざわざループの外でdouble = []という配列を用意して、さらにループの中でdouble << i * 2とdoubleに追加するところまで書くのは、他の言語ならともかく、Ruby的には非常にイケてない冗長な書き方です。
list = (1..5).to_a.freeze
double = [] # 空のdoubleをわざわざ用意している☹
list.each do |i|
double << i * 2 # doubleの組み立てまでやっている☹
end
puts "2倍したリスト: #{double}"
#=> 2倍したリスト: [2, 4, 6, 8, 10]
![⚓]()
#mapならこう書ける
上の例を#mapメソッドで書き直すと以下のようにずっと簡潔に書けます。#mapは結果を配列で返します。
list = (1..5).to_a.freeze
mapped = list.map do |i|
i * 2 # やりたいことはこれだけ😄
end
puts "2倍したリスト: #{mapped}"
#=> 2倍したリスト: [2, 4, 6, 8, 10]
参考: Enumerable#collect (Ruby 2.7.0 リファレンスマニュアル) — mapはcollectのエイリアスです
まず、doubleという変数を用意せずに済むというメリットがあります。
そしてもっと重要なのは、#mapの場合は「要素ごとにやって欲しい処理を外から渡す」という発想になっていることです。#mapに渡されているdo–endブロックの中にあるのはi * 2だけで、処理の本質だけがずばりと記述されています。
先の#eachは「やりたいことをループの中で逐一記述する」というforと変わらない発想なので、本質的な処理以外に結果の組み立て方法まで記述しています。ある程度以上複雑な処理であればそのように記述するのもわかりますが、この処理をわざわざ#eachで書くのは車輪を再発明しているようなものです。
配列の各要素に処理を加えたものを返すという定型的な処理であれば、#mapや#injectやeach_with_objectのようなEnumerableのコレクション系メソッドを使う方が遥かに簡潔かつ読みやすくなります。
単にこういう場合は#mapを使いましょうというだけではなく、「ループ内に処理を逐一記述する」という手続き的発想から「処理をEnumerableのメソッドに渡す」というRubyらしい発想に切り替えるところがポイントです。
![⚓]() 参考:
参考: #mapを#eachで実装して理解する
# オレオレmap
def my_map(collection, &block)
result = []
collection.each do |element|
result << yield(element)
end
result
end
list = (1..5).to_a.freeze
my_mapped = my_map(list) do |element|
element * 2
end
puts "my_mappedの結果: #{my_mapped}"
#=> my_mappedの結果: [2, 4, 6, 8, 10]
![⚓]()
#inject
次は#injectです(#injectには#reduceというエイリアスメソッドもあります)。
参考: Enumerable#inject (Ruby 2.7.0 リファレンスマニュアル)
以下は配列の合計を求める簡単なコードですが、これも#eachでやろうとすると冗長かつ非効率になります。
list = (1..5).to_a.freeze
sum = 0 # 残念
list.each do |i|
sum += i # 残念
end
puts "eachによる合計: #{sum}"
#=> eachによる合計: 15
これも次のように#injectで簡潔に書けます。理由は#mapの場合と同じです。
list = (1..5).to_a.freeze
inject_sum = list.inject(0) do |i, j|
i += j
end
puts "injectによる合計: #{inject_sum}"
#=> injectによる合計: 15
![⚓]() 補足:
補足: #sumは高速
ここでは発想の転換を説明するためにあえて#injectで書いていますが、現実に配列内の数値の合計を求めるなら、#sumメソッドを使ってlist.sumと書く方が遥かに簡潔かつ高速です。特にrangeで表された数値の合計を求める場合は#sumが断然高速です。
参考: Array#sum (Ruby 2.7.0 リファレンスマニュアル)
参考: ruby - Why is sum so much faster than inject(:+)? - Stack Overflow
ただし文字列や配列(この場合結合されます)については、#sumより#joinやflattenの方が高速です。
参考: Array#join (Ruby 2.7.0 リファレンスマニュアル)
参考: Array#flatten (Ruby 2.7.0 リファレンスマニュアル)
![⚓]() 参考:
参考: #injectを#eachで実装して理解する
# オレオレinject
def my_inject(collection, init, &block)
folding = init
collection.each do |element|
folding = yield(folding, element)
end
folding
end
list = (1..5).to_a.freeze
my_inject_sum = my_inject(list, 0) do |i, j|
i += j
end
puts "my_injectによる合計: #{my_inject_sum}"
#=> my_injectによる合計: 15
![⚓]() ハッシュもコレクションとして扱える
ハッシュもコレクションとして扱える
まずはハッシュを#eachで扱う例です。
hash = { a: 1, b: 2, c: 3 }.freeze
hash.each do |key, value|
puts "キー #{key} の値は: #{value}"
end
Rubyには既にHash#invertというハッシュのキーと値を入れ替えたものを返すメソッドがありますが、これを#mapで再実装するとたとえば次のように書けます。
hash = { a: 1, b: 2, c: 3 }.freeze
inverse = hash.map do |key, value|
[value, key]
end.to_h
puts "inverse: #{inverse}"
#mapが返すのはあくまで配列なので、最後に#to_hでハッシュに変換しています。
![⚓]() ハッシュの
ハッシュの#injectは少々注意
ハッシュもコレクションなので、#injectで扱えます。しかし以下のサンプル(ハッシュの値を合計する)を実行するとno implicit conversion of Symbol into Integerが返ります。どこに問題があるかわかりますか?
# コケるinject
hash = { a: 1, b: 2, c: 3 }.freeze
begin
sum_hash = hash.inject({ sum: 0 }) do |r, (key, value)|
r[:sum] += value # 👀
end
puts "sum_hash???: #{sum_hash}"
rescue => e
puts "エラーですよ: #{e}"
end
#=> エラーですよ: no implicit conversion of Symbol into Integer

上のスライドをご覧ください。先のコードで#injectに渡したブロックの中にあるのはr[:sum] += valueになっています。#mapなら処理の結果を気にする必要がないのでラクですが、#injectは処理の結果が次の繰り返しの初期値に送り込まれるので、そこをケアする必要があります。
エラーの原因は「処理の最終行でrではなくr[:sum]が返されていたこと」です。1回目の繰り返しではr[:sum]の値は1になりますが、それが2回目の繰り返しに送り込まれると1[:sum]という無意味なハッシュになったことでエラーが発生していました。
この場合、以下のように最終行でハッシュを明示的にrで返す必要があります。
hash = { a: 1, b: 2, c: 3 }.freeze
sum_hash = hash.inject({ sum: 0 }) do |r, (key, value)|
r[:sum] += value
r # これ必要!
end
puts "sum_hash: #{sum_hash}"
#=> sum_hash: {:sum=>6}
![⚓]() それ、
それ、#each_with_objectでできるよ
「いちいちrを最後に置くの面倒」とお思いの方は、以下のように#each_with_objectを使えば最終行にrを置かずにスマートに書けます。
hash = { a: 1, b: 2, c: 3 }.freeze
each_with_object = hash.each_with_object({ sum: 0 }) do |(key, value), r|
r[:sum] += value # 今度は大丈夫😋
end
puts "each_with_object: #{each_with_object}"
#=> each_with_object: {:sum=>6}
![⚓]() 参考:
参考: #each_with_objectを#eachで実装して理解する
# オレオレeach_with_object
def my_each_with_object(collection, init, &block)
folding = init
collection.each do |element|
yield(element, folding)
end
folding
end
hash = { a: 1, b: 2, c: 3 }.freeze
my_each_with_object_sum =
my_each_with_object(hash, { sum: 0 }) do |(key, value), r|
r[:sum] += value
end
puts "my_each_with_object_sum: #{my_each_with_object_sum}"
#=> my_each_with_object_sum: {:sum=>6}
![⚓]()
#injectと#each_with_objectの違いは「副作用」にあり
先のコード例からも、#each_with_objectの挙動は#injectととても似ていることがわかりますが、違っている点もあります。それぞれの擬似コードを横に並べて見比べてみると、ほんのわずかな違いがあります。
注: 擬似コードは挙動の理解のためにこしらえたもので、実装がこのとおりかどうかについては未確認です。

両者の違いは以下の部分です。
#injectfolding = yield(folding, element)#each_with_objectyield(element, folding)
#injectの方は、folding(この値が次の繰り返しに送り込まれる)に単にyield(folding, element)の結果を代入しています。
#each_with_objectの方は、yield(element, folding)を返しているだけで、foldingに対して操作を何も行っていません。ということは、このyieldで実行されるブロックが「foldingを改変している」、つまり渡すブロックに副作用がある場合にのみ機能するということになります。
逆に言えば、#each_with_objectに渡すブロックが副作用を伴わない場合は機能しません。以下はブロックの処理r += iで配列を改変しないので、結果は0のままです。
# 副作用なしの場合
list = (1..5).to_a.freeze
my_each_with_object_fixnum_sum = list.each_with_object(0) do |i, r|
r += i # 元のlistを改変していない
end
puts "my_each_with_object_fixnum_sum: #{my_each_with_object_fixnum_sum}"
# => my_each_with_object_fixnum_sum: 0
#each_with_objectならば最後にわざわざrを明示的に返さなくても動作するのは、ブロック内のr:[sum] += valueという処理がハッシュを改変しているから、というのが理由です。
![⚓]() おまけ1
おまけ1
#injectと#each_with_objectには、実はもうひとつ微妙な違いがあります。
Rubyの実際の#injectと#each_with_objectはどちらもブロック引数を2つ取りますが、なぜかブロック引数の順序が互いに逆になっています↓。
# inject
[1, 2, 3].inject [] do |result, i|
result << i**i
end
#=> [1, 4, 27]
# each_with_object
[1, 2, 3].each_with_object [] do |i, result|
result << i**i
end
#=> [1, 4, 27]
本記事の擬似コードでは順序を同じにしていますのでご注意ください。
![⚓]() まとめ
まとめ
- どんなときも
#eachメソッドを使うのは、どんなときもfor文を使っているのと変わらない - コレクション系のメソッドは
#eachで実装できる #eachで車輪の再発明をするより、他のコレクション系メソッドでできないかを先に検討しよう
今回取り上げたメソッドをまとめると次のようになります。
| メソッド | 用途 | 戻り値 |
|---|---|---|
#each |
コレクションの各要素で処理を回す | コレクション自身(変更された要素を含む) |
#map |
コレクションの各要素を変換する | 新しいコレクション(変更された要素を含む) |
#inject |
コレクションから新しいものを作る(初期値は非破壊) | 別の何か(通常は初期値の型になる) |
#each_with_object |
コレクションから新しいものを作る(初期値を破壊) | 別の何か(各要素が初期値に破壊的に作用した結果) |
ツイートより
Rubyのループ処理は
eachよりmap, inject, each_with_object
を使った方がいい時もあるんだなRuby: `each`よりも`map`などのコレクションを積極的に使おう(勉強会) https://t.co/Oy7XEG1OyS
— プログラミングを仕事にしたいマン
(@doryo9999) July 21, 2018
 (@doryo9999)
(@doryo9999) 今まで困るとすぐeach大魔神してるとこあったのであらためねば https://t.co/4E62MovPpg
— すろっくさん (@srockstyle) July 24, 2018







 」「コミットやプルリクのmerge順次第では、未実行のマイグレーション番号が常に最新の番号とは限らないけど、マイグレーション番号単位で具体的に未実行のものが分かるようになるのか」
」「コミットやプルリクのmerge順次第では、未実行のマイグレーション番号が常に最新の番号とは限らないけど、マイグレーション番号単位で具体的に未実行のものが分かるようになるのか」


 Railsアプリに最適なEC2インスタンスタイプとは(
Railsアプリに最適なEC2インスタンスタイプとは(
 」
」 」
」




 With it, we aim to simplify the use and setup of MeiliSearch even more
With it, we aim to simplify the use and setup of MeiliSearch even more  . With implicit index creation, you now only need to add documents to start searching.
. With implicit index creation, you now only need to add documents to start searching. 











 」「RubyのSTMはどこかで見かけたような気がする(注: 後述の笹田さん資料を参照)」「詳しい人に教わりたいです」
」「RubyのSTMはどこかで見かけたような気がする(注: 後述の笹田さん資料を参照)」「詳しい人に教わりたいです」






 」
」
 Yamada_Nt (@yamada_nt)
Yamada_Nt (@yamada_nt)  」「あのイルカ」「あのイルカだ」「あのイルカ、見かける機会が既になくなりましたよね」「若い世代だとほとんど知らないんじゃないかしら」「インターネットミームの一種か何かと思われてたりして
」「あのイルカ」「あのイルカだ」「あのイルカ、見かける機会が既になくなりましたよね」「若い世代だとほとんど知らないんじゃないかしら」「インターネットミームの一種か何かと思われてたりして
 」「あれを一度でも経験すると身に沁みます」
」「あれを一度でも経験すると身に沁みます」

 。お気づきの点がありましたら
。お気づきの点がありましたら
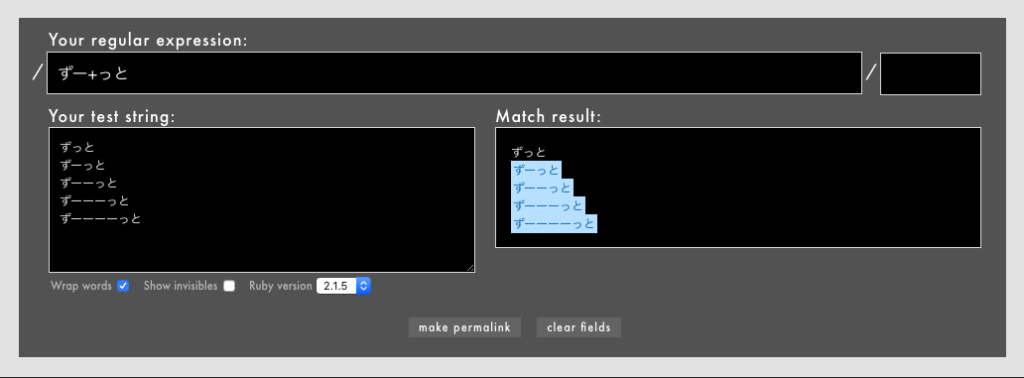
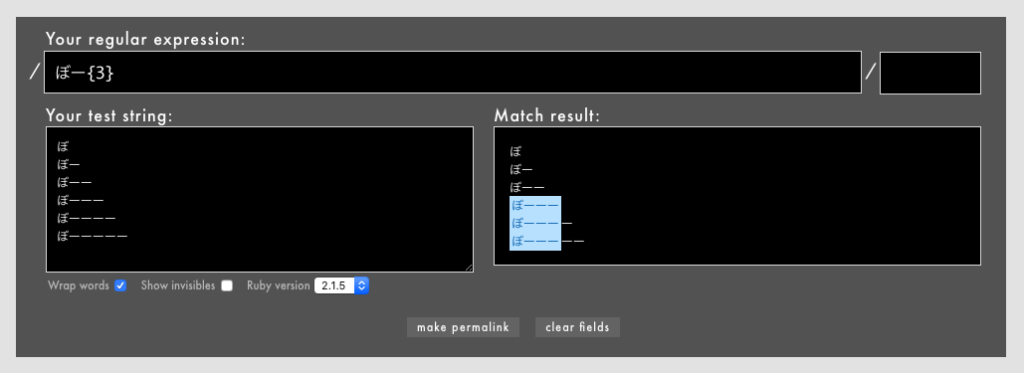
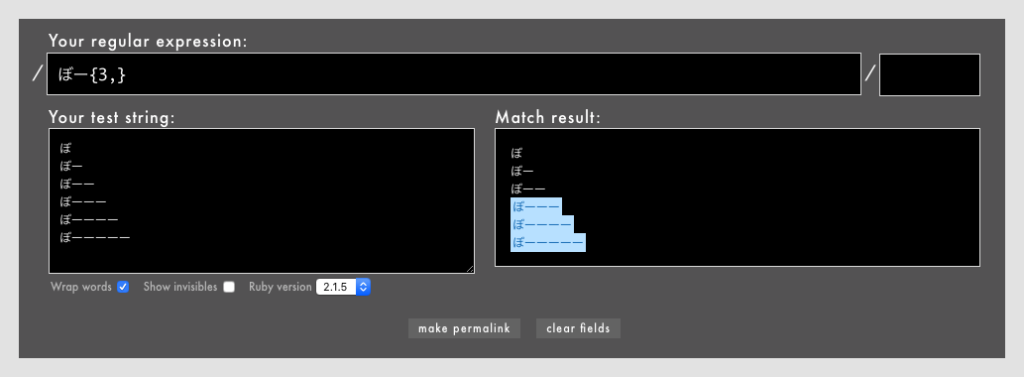
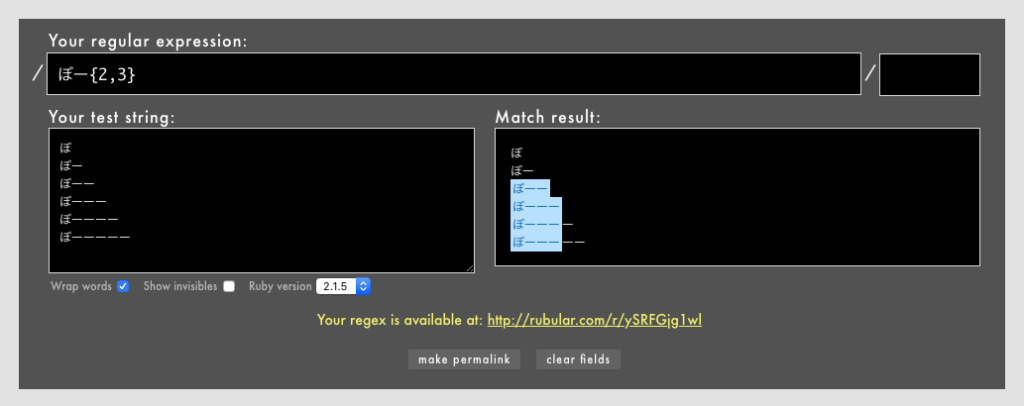
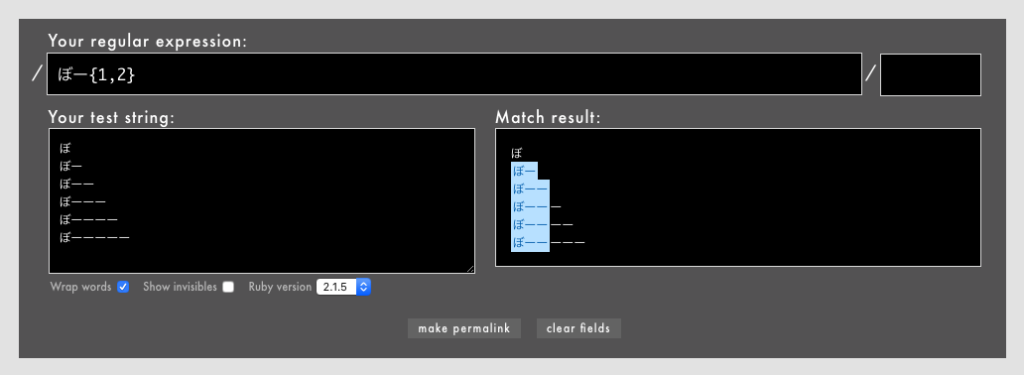
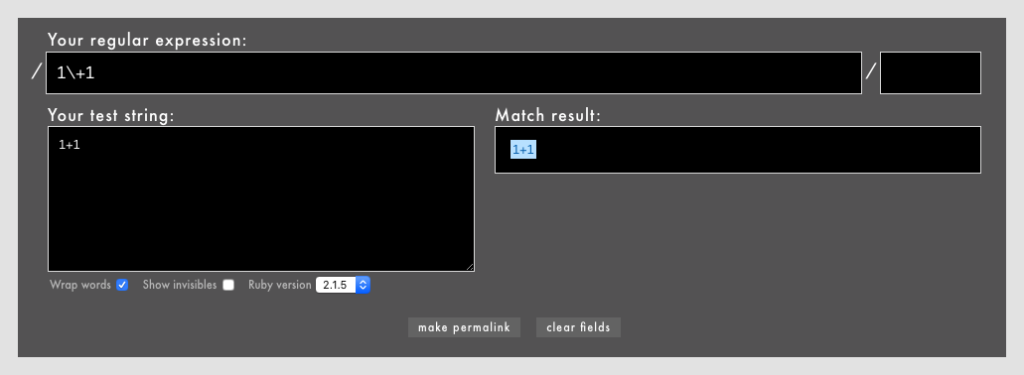
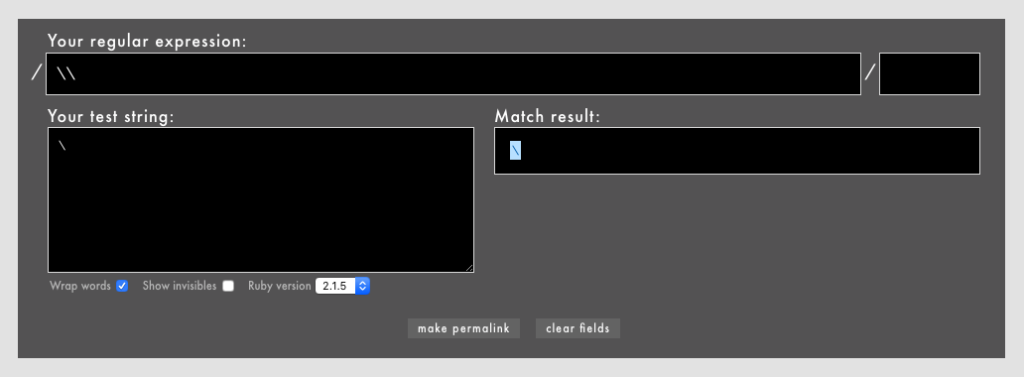
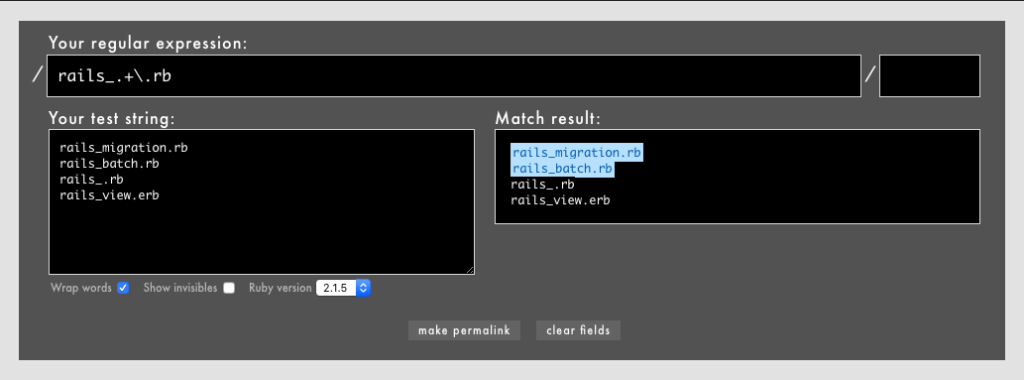
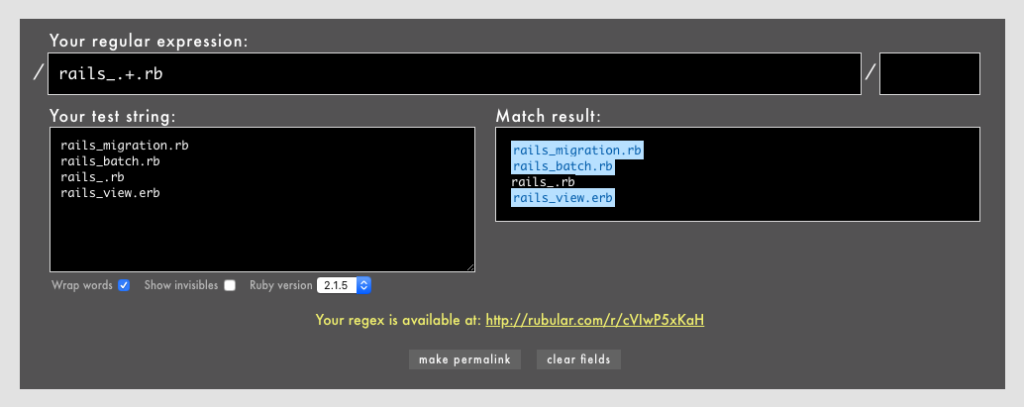
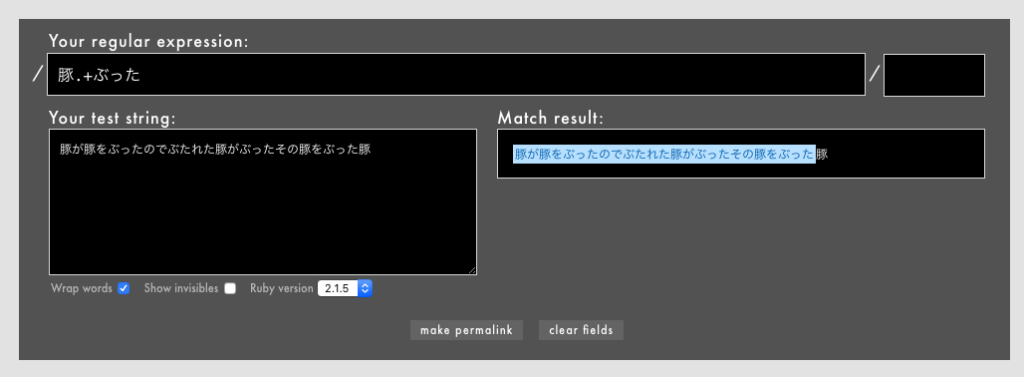
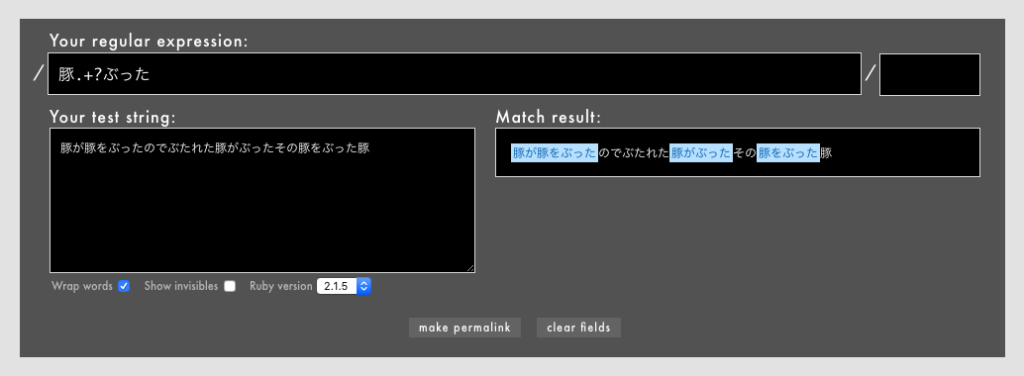
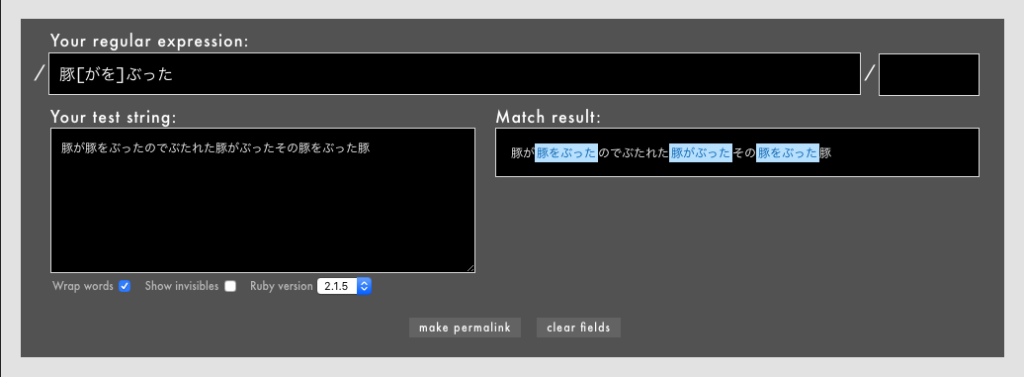
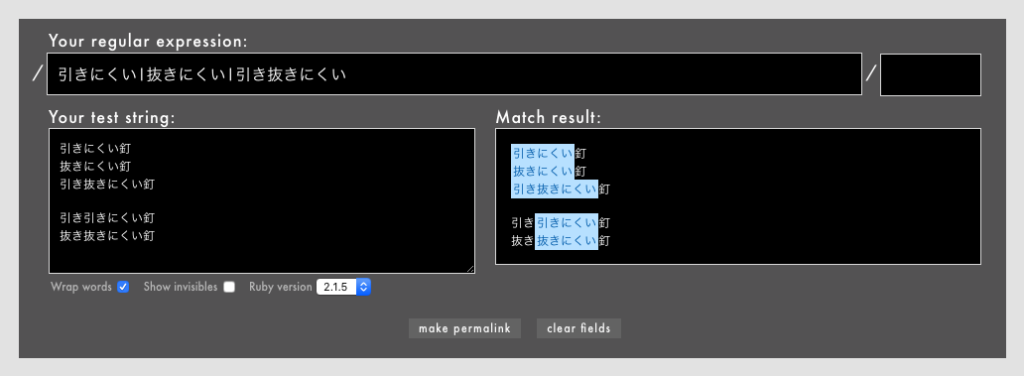
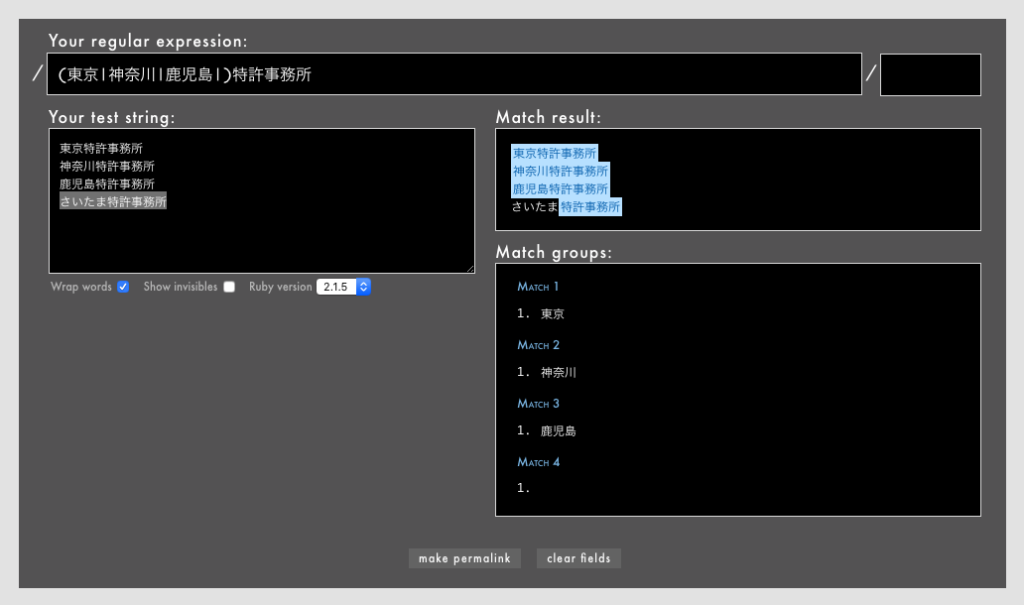
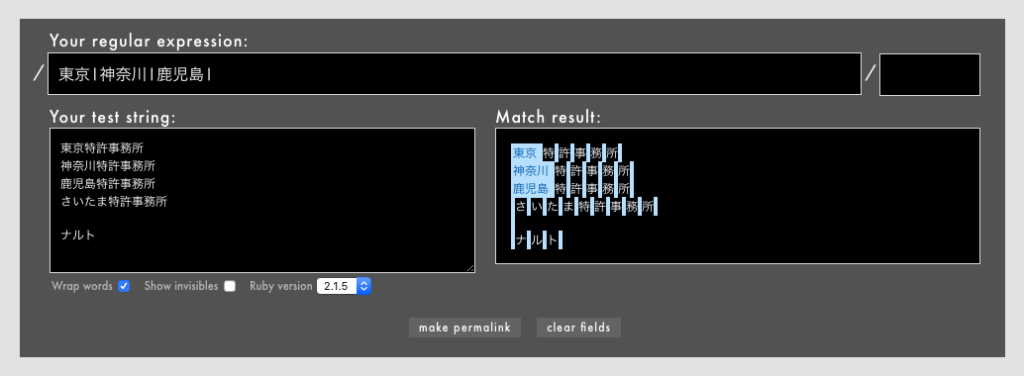






















 」「ワンラインパターンマッチングなどの一部のパターンマッチング機能はまだexperimentalなのか」「これで3.0になったらパターンマッチングを使ってもよくなりますね
」「ワンラインパターンマッチングなどの一部のパターンマッチング機能はまだexperimentalなのか」「これで3.0になったらパターンマッチングを使ってもよくなりますね 」「たしかにそのとおりなんですけど、これを意識的に使う機会ってあるんだろうか?」「
」「たしかにそのとおりなんですけど、これを意識的に使う機会ってあるんだろうか?」「








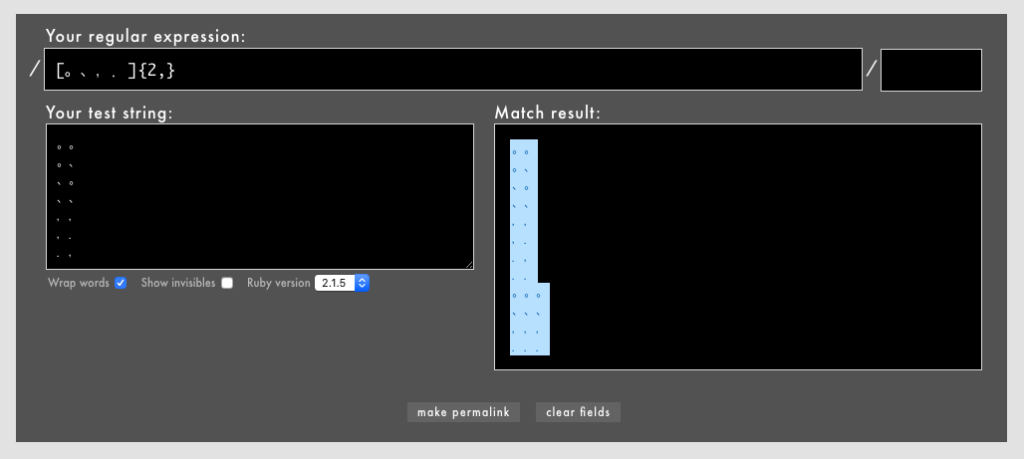





















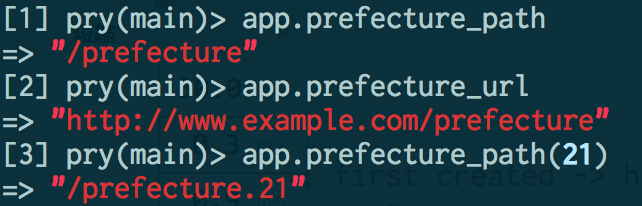

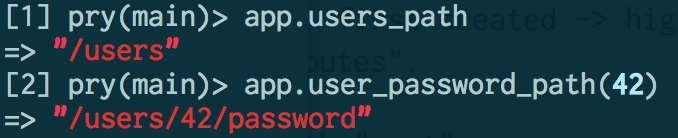




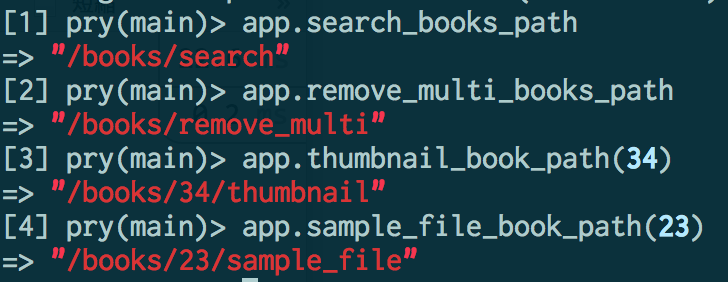





 」「これができないと不便なんですよ: 今まではhealthcheckを受信するためにALB healthcheck用のIPアドレス範囲設定が必要でした」
」「これができないと不便なんですよ: 今まではhealthcheckを受信するためにALB healthcheck用のIPアドレス範囲設定が必要でした」



 」
」

 」「自分の尻尾は美味い
」「自分の尻尾は美味い





#morimorihoge注:
※本記事の内容は賃貸物件であれば大家との契約、所有物件の場合でもマンション管理規約等に抵触する可能性があります。
恐らく通常は問題ない範囲のhackかと思いますが、参考に当たっては自己責任でお願いします。